業界専用モデルの機械翻訳 共同開発プロジェクト
「製薬カスタムモデル」の展開について
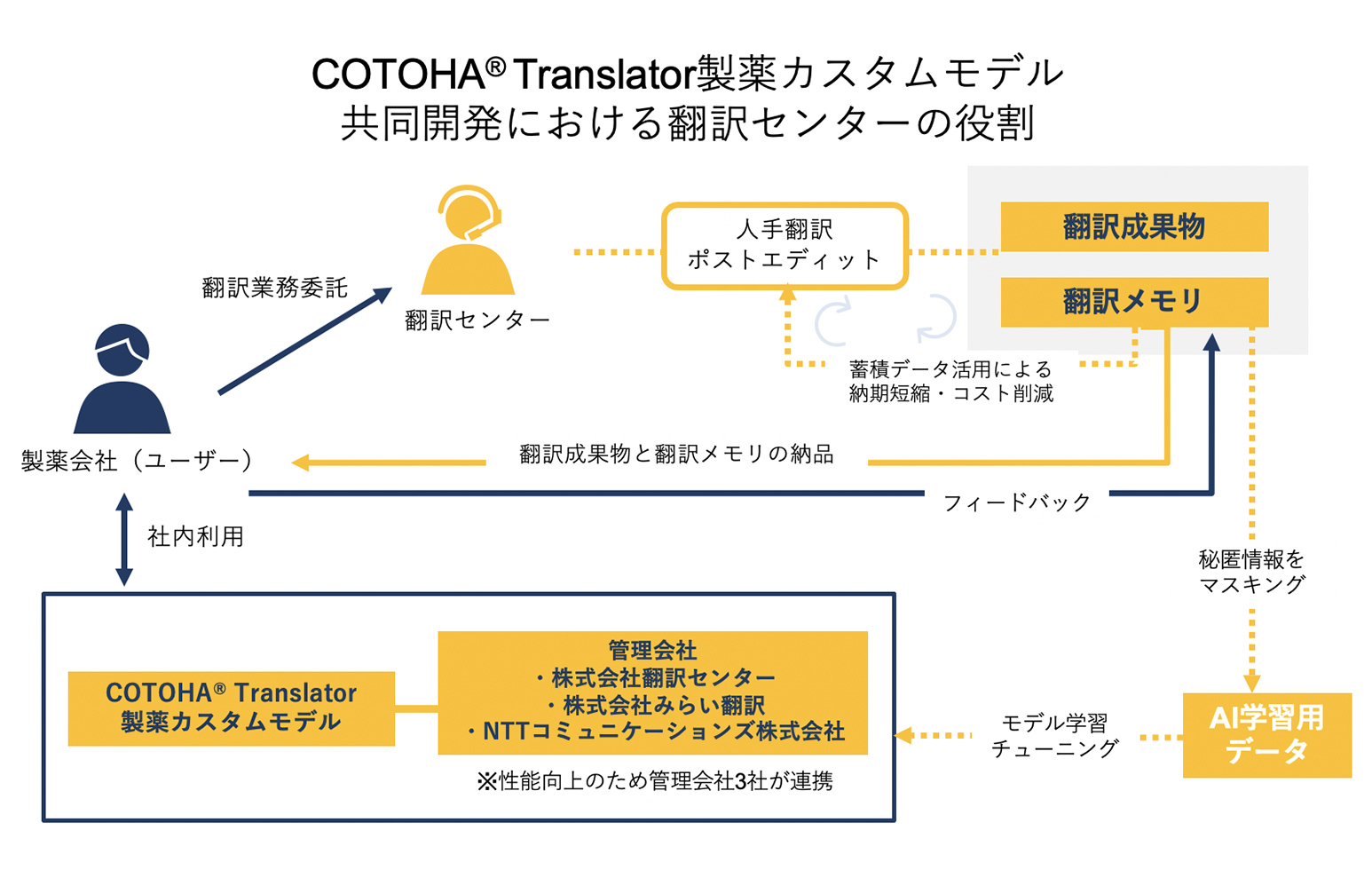
翻訳会社だからこそできる改善策
長年にわたる製薬会社への翻訳業務支援のなかで、
規制当局への申請文書作成に多大な時間を費やしているという課題に対し、各製薬会社が保有する翻訳データを収集して製薬業界専用モデルの機械翻訳を開発することが解決策になると考え、プロジェクトは始動しました。

製薬会社12社からの翻訳データ提供により
約2年の開発期間を経て販売を開始
「製薬カスタムモデル」は、参画メンバー12社から収集した翻訳データに
独自処理を施してコーパス化したものを機械翻訳にモデル学習させ、
お客さまにそのプラットフォームを提供するいう仕組みです。
分野特化モデルの構築にはある程度大量のコーパスが必要と言われていますが、
新たなコーパスを追加学習させることで、さらなる精度向上が期待できます。
製薬カスタムモデルイメージ
翻訳データ(原文・翻訳文)のコーパス化*
何重にもセキュリティをかけた社内の当プロジェクト専用サーバー

- 当プロジェクト専用のローカルサーバーを使って作業
- データ処理技術を熟知する限られた人間が作業
翻訳データ
(原文・翻訳文)の
アライメント

アライメントした
データをマスキング

モデル学習・
チューニング

製薬カスタムモデル
カスタムモデル参画メンバー以外には非公開

- 顧客指定のクラウドストレージを使用
- 翻訳データは暗号化して送受信、ダウンロード後は削除
- クラウドストレージ使用以外に直接受け渡しを行う場合もあります。
翻訳データ(原文・翻訳文)のご提供
カスタムモデル参画メンバー各社

* グループ会社内での作業
強固なセキュリティ環境のもとで作業
お客さまから翻訳データをお預かりする際は、お客さま指定のクラウドストレージを使い、暗号化した上で送受信を行っていますが、
場合によっては直接、お客さまのもとに翻訳データをお預かりに伺うこともあります。
お客さまから受領した翻訳データはアライメントした後、顧客名・薬剤名・化合物名などの情報をマスキングすることにより個社特定につながる情報を秘匿化。
これら 一連の作業は限定された人間が行い、データ自体もローカルサーバー上で管理するため、外部からのアクセスは一切できません。
事例紹介
![]() 小野薬品工業株式会社
小野薬品工業株式会社
創業300有余年の老舗製薬会社が導入した
COTOHA® Translator製薬カスタムモデルとグローバル化への展望を語る
新薬を世界中の患者さんに迅速に提供できるよう、グローバル化への体制の整備・強化、また、スピード化を念頭にさまざまな戦略を策定している製薬会社・小野薬品工業株式会社。1717年の創業以来、製薬一筋に邁進してきました。グローバル スペシャリティファーマを目指した取り組みを進めている同社は、COTOHA® Translator製薬カスタムモデルのコンソーシアム第一期メンバーとなり、10社を超える製薬会社と共にモデルの開発から参画し、現在は全社でCOTOHA® Translator製薬カスタムモデルを導入いただいています。